
ワード頻出度を表示する

ワード頻出度
この画像のように、取り込んだデータや特定のノードでコーディングされたソースを対象としてどのような言葉が利用されているのかを簡単に取り出すことができます。
以前のバージョンと比べましてNVivo10から日本語の解析が改善され、日本語の環境でも使い勝手が良くなりました。ではその方法をご紹介します。
*NVivo 11 for Windows をご利用の方は、頻出語を特定する(NVivo 11) をご覧ください。
*本操作の前に、データの取り込みが必要となります。
1.クエリウィザードを実行する。
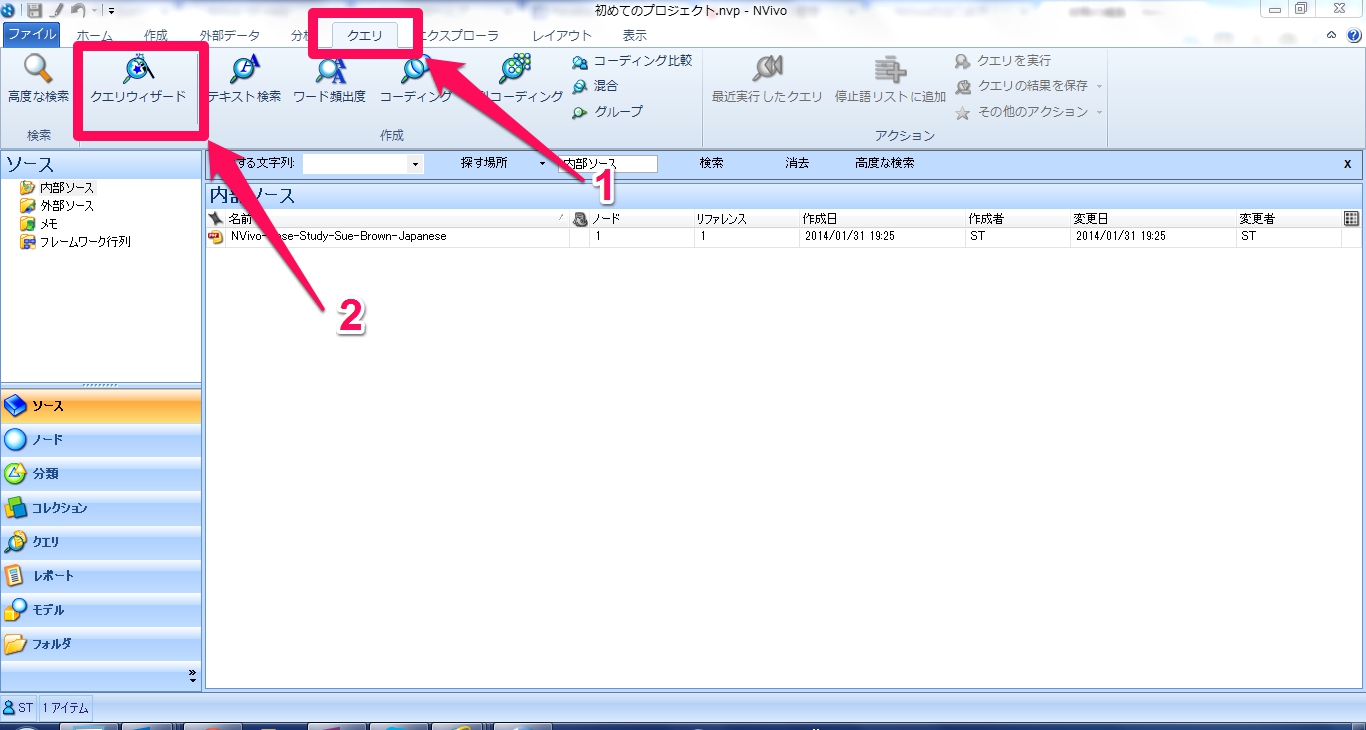
クエリウィザードの起動
画面上部のクエリ>クエリウィザードと進みます。
2.クエリウィザードに従って、進めていきます。
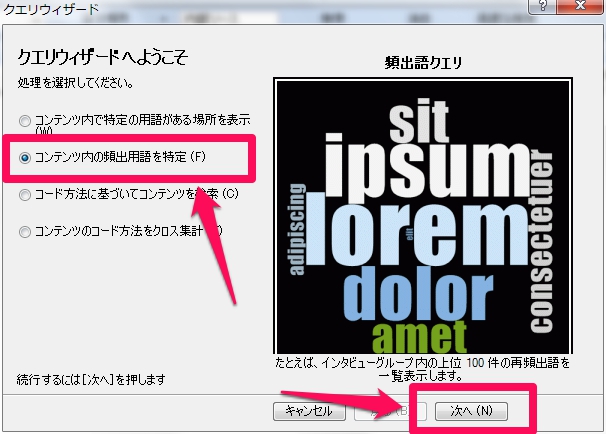
クエリウィザードへようこそ
この画面で”コンテンツ内の頻出用語を特定”を選択し、次へ。
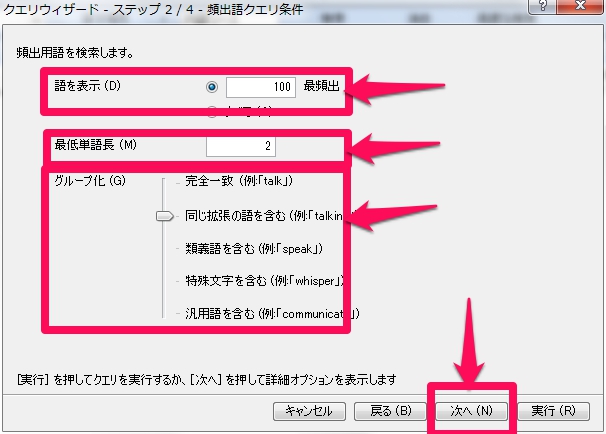
クエリウィザード – 頻出語クエリ条件
まずは画面のように
語を表示 : 100
最低単語長:2
グループ化: 同じ拡張の語を含む
として進めてみましょう。
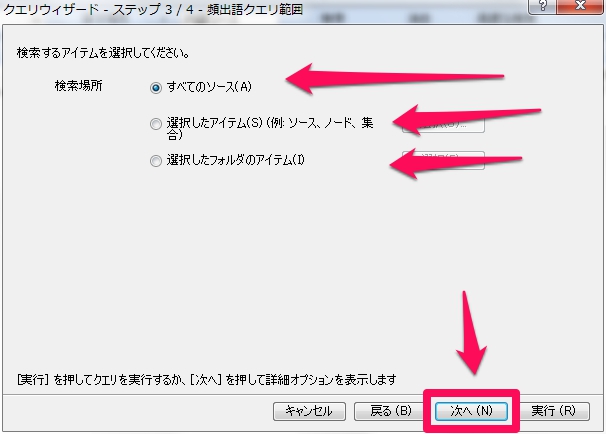
クエリウィザード – 頻出語クエリ範囲
全てのソースを選択します。
“選択したアイテム”では、特定のソースや特定のノード内に含まれる単語を指定できます。
“選択したフォルダのアイテム”では、フォルダ単位で整理されているグループ内のソースやノードから頻出語を検索してきます。

クエリウィザード – プロジェクトに追加
“このクエリを一回実行”を選択して、”実行”をクリックすると、結果が表示されます。
*”このクエリをプロジェクトに追加”を選択した場合には、このクエリを後から実行するときにこの条件を保存することができます。
3.結果の表示
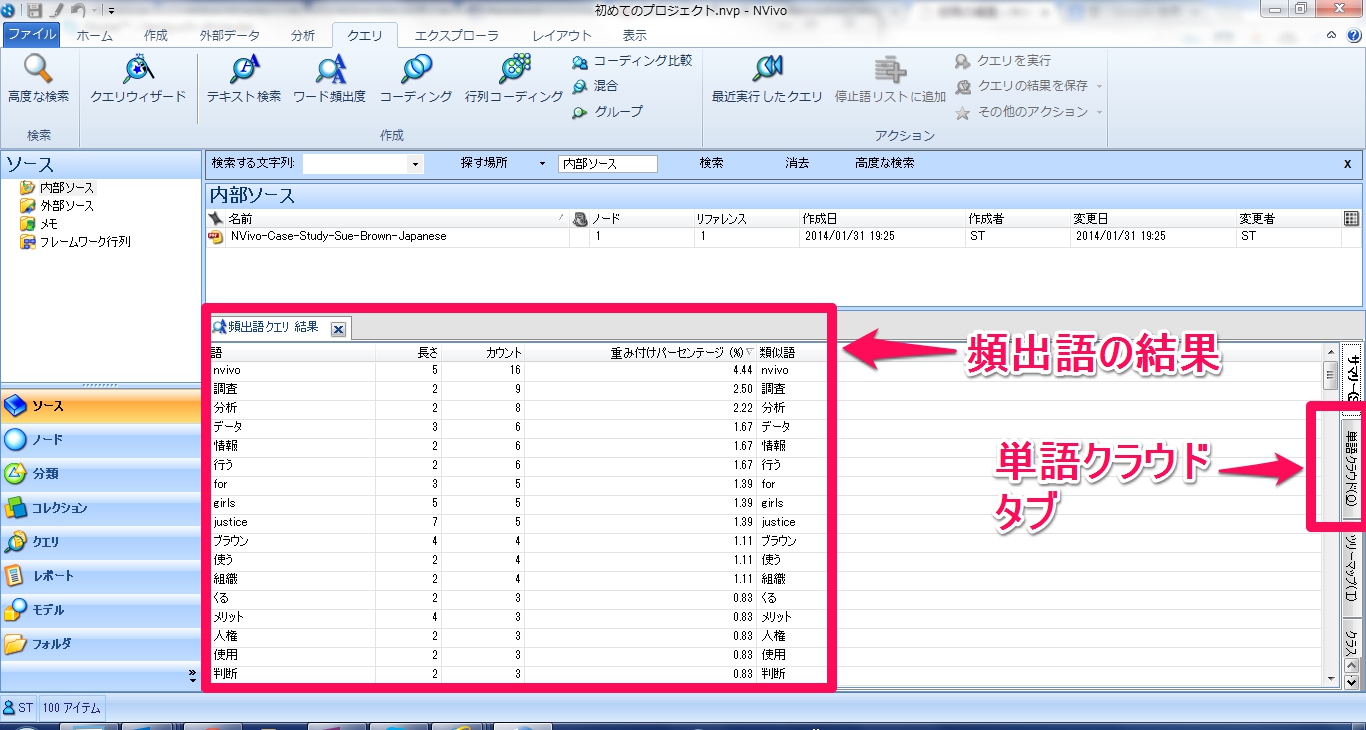
頻出語クエリ結果
表示された頻出語の結果は表形式になっていますので、右側に現れる”単語クラウド”を選択しましょう。
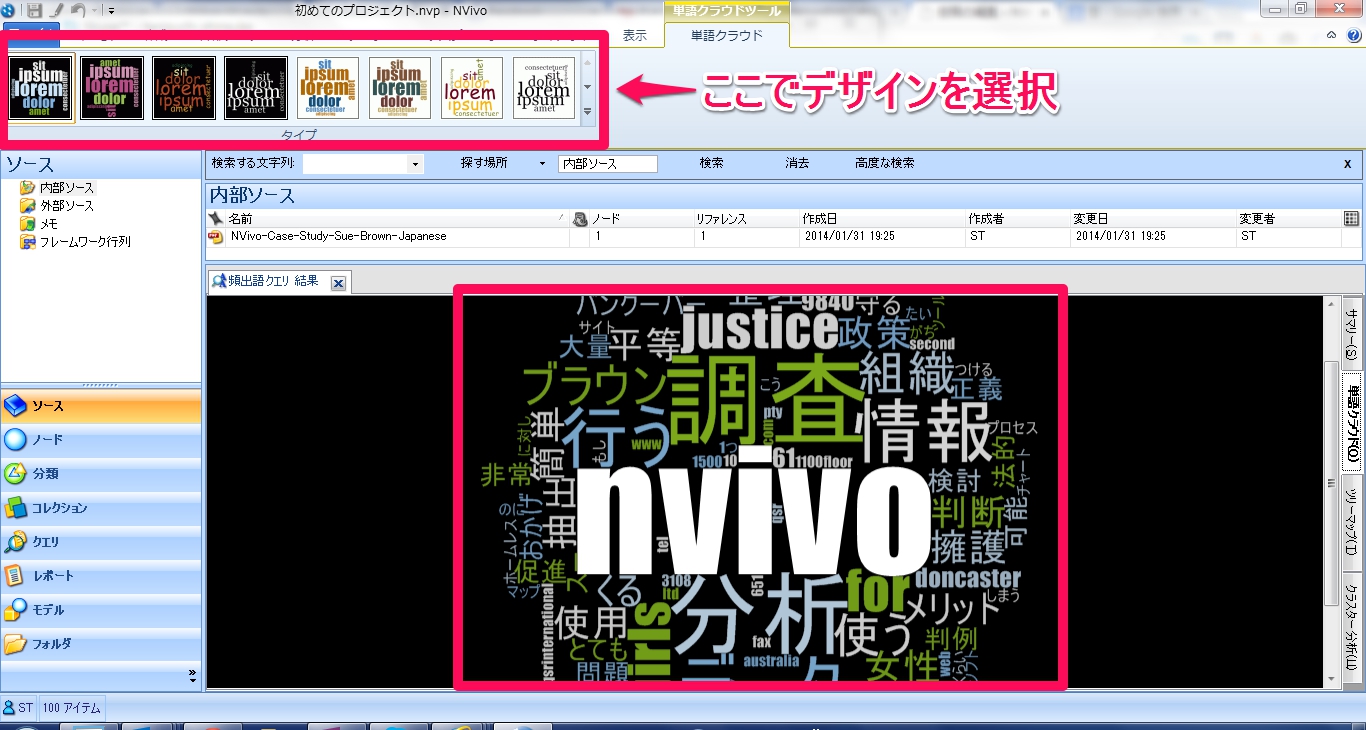
頻出語クエリ – 単語クラウド
単語クラウドが表示されました。
追記) この画面の気になる単語の上で右クリック → テキスト検索クエリ と辿ると、すばやくその単語を中心としたワードツリーの表示に事もできます。詳しくはワードツリーを表示するの2番目以降の手順をご参照ください。
以上です。ご不明点などありましたら、コメントください。
関連記事
-

-
頻出語クエリで日本語が表示されない(NVivo 11)
英語だけの単語クラウド[/caption] 頻出語クエリで日本語が出てこず、英語だけの結果が
-
-
テキスト検索クエリの結果をワードツリーで表示する
NVivo ではご自身の研究に必要なドキュメントから、単語を指定してその単語の前後でどのような事が述
-
-
クエリオプションを使いこなす – 対象範囲を指定する
クエリ設定画面[/caption] テキスト検索クエリやワード頻出度クエリには、検索条件とし
-
-
ワード頻出度クエリで日本語が出ない→言語変更で解決(NVivo 10)
英語だけの単語クラウド[/caption] ワード頻出度クエリで日本語が出てこない場合、プロ
-

-
資料から一瞬で必要な文章を取り出す「テキスト検索クエリ」(NVivo 11)
調査・研究で必要な資料が集まって、その中から特定の単語を探し出すというのはとても骨の折れる作
-
-
クエリを保存する方法
何度も使うクエリはクエリウィザードの設定中にクエリを保存しておくのが良いです。例えば一度分析したプロ
-
-
ワードツリーを最前面に – テキスト検索クエリ結果プレビュー
「テキスト検索クエリを実行したら、真っ先にワードツリーを見たい!」そんな時はテキスト検索クエリ結果プ
-

-
コーディングクエリを使う
ノードをダブルクリックするとそこにコーディングされているテキストなどのリファレンスを見ることができま
-

-
頻出語を特定する(NVivo 11)
頻出語[/caption] 集めてきたデータを俯瞰してみてみたいとき、NVivoでは頻出語と
-
-
テキスト検索クエリを使う
調査・研究で必要な資料が集まって、その中から特定の単語を探し出すというの


Comment
[…] 実行方法についてはワード頻出度クエリの実行をご参照ください。 […]