頻出語を特定する(NVivo 11)
公開日:
:
クエリ NVivo 11 for Windows, 頻出語

頻出語
集めてきたデータを俯瞰してみてみたいとき、NVivoでは頻出語としてまずデータを眺めてみることができます。一部特定のデータだけに絞ったり、特定ノードでコーディングされたデータのみを対象としてどのような言葉が利用されているのかを見ることによって今まで注目していなかった事実を発見することができるかもしれません。以前のバージョンと比べましてユーザーインターフェイスを改善し、再実行を行いやすくなっています。ではその方法をご紹介します。
*この記事はNVivo 11 Pro for Windowsを使用して作成しました(NVivo 11 Starter for Windows では設定項目に一部制限があります)。
*NVivo 10 for Windows をご利用の方は、ワード頻出度を表示する(NVivo 10) をご覧ください。
*本操作の前に、データの取り込みが必要となります。
1.頻出語クエリを立ち上げる
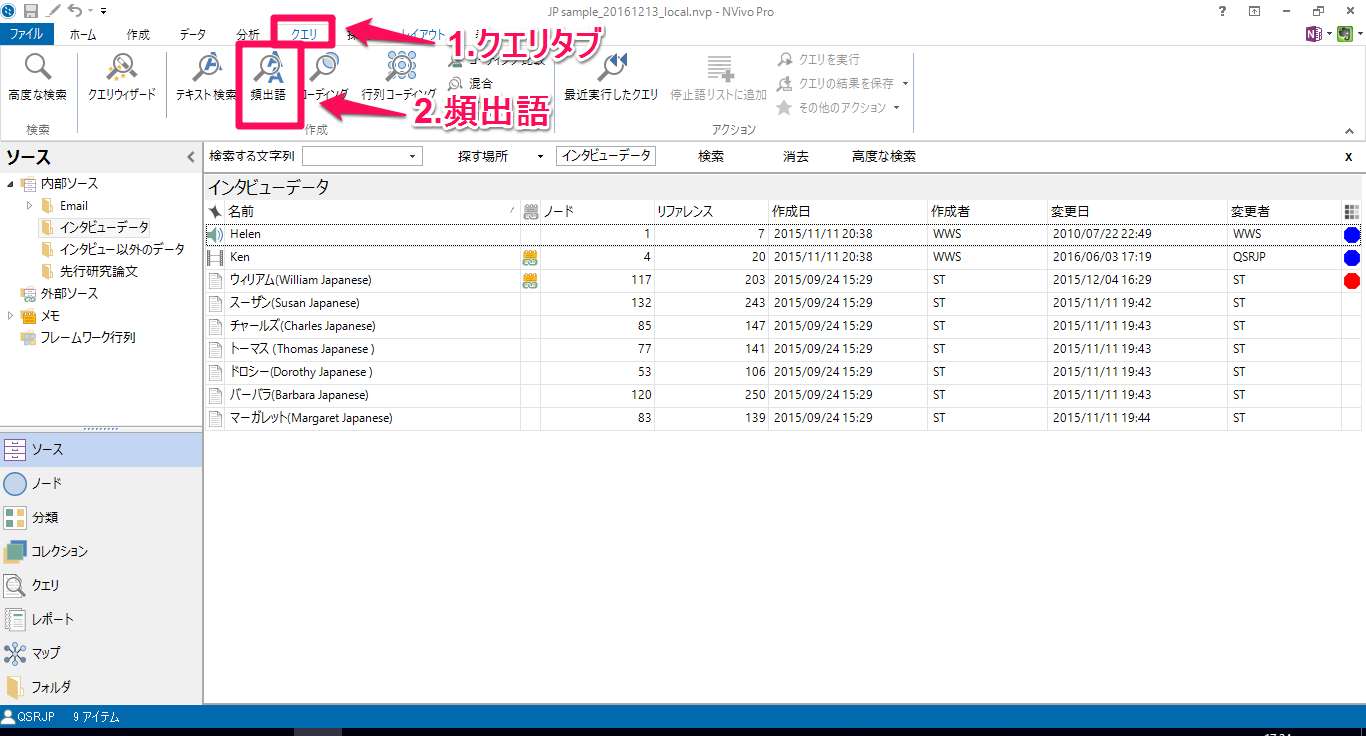
画面上部リボンメニューから、クエリ > 頻出語 をクリックします
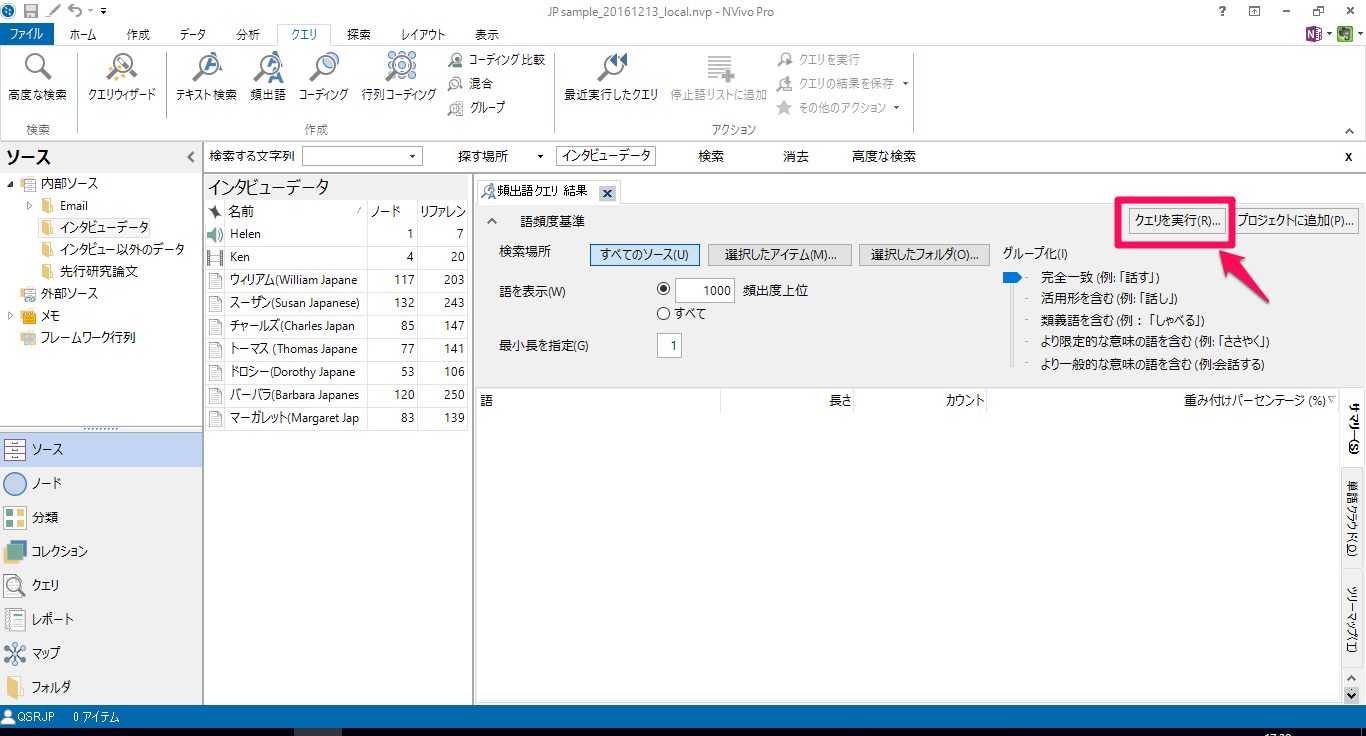
クエリを実行をクリックします(標準状態のままで実行してみましょう)
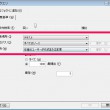
このクエリ画面で様々な設定ができます
- 語を表示では、上位何件までの結果を表示するかを設定します
- 最低単語長では、検索対象とする単語の長さを指定します。例えば 3 で設定した場合には、「」
- 検索場所には3つの選択肢がありますが、検索の対象とする場所を設定できます。「すべてのソース」を選択(標準状態)ではソースに入力されているすべてのデータに対して検索を行います、「選択したアイテム」を選ぶと、特定のインタビューだけ、特定のノードに関連づけられている文章のみから探すのかといった設定が可能です。「選択したフォルダ」 では、検索対象とする場所をフォルダ単位で設定するときに使用します。
- “グループ化”では、”完全一致”から”より一般的な語を含める”まで5段階を選択できますが、例えば頻出語に「スポーツ」という言葉が登場した時、一番上の”完全一致”を選択した場合はその単語のみを集計した結果を返します。スライダーを下に寄せ”より一般的な語を含める”にすると、スポーツという単語の他に”バスケットボール”などの類似語を含めて頻度を算出します。
お好みで設定を行ってみてください。
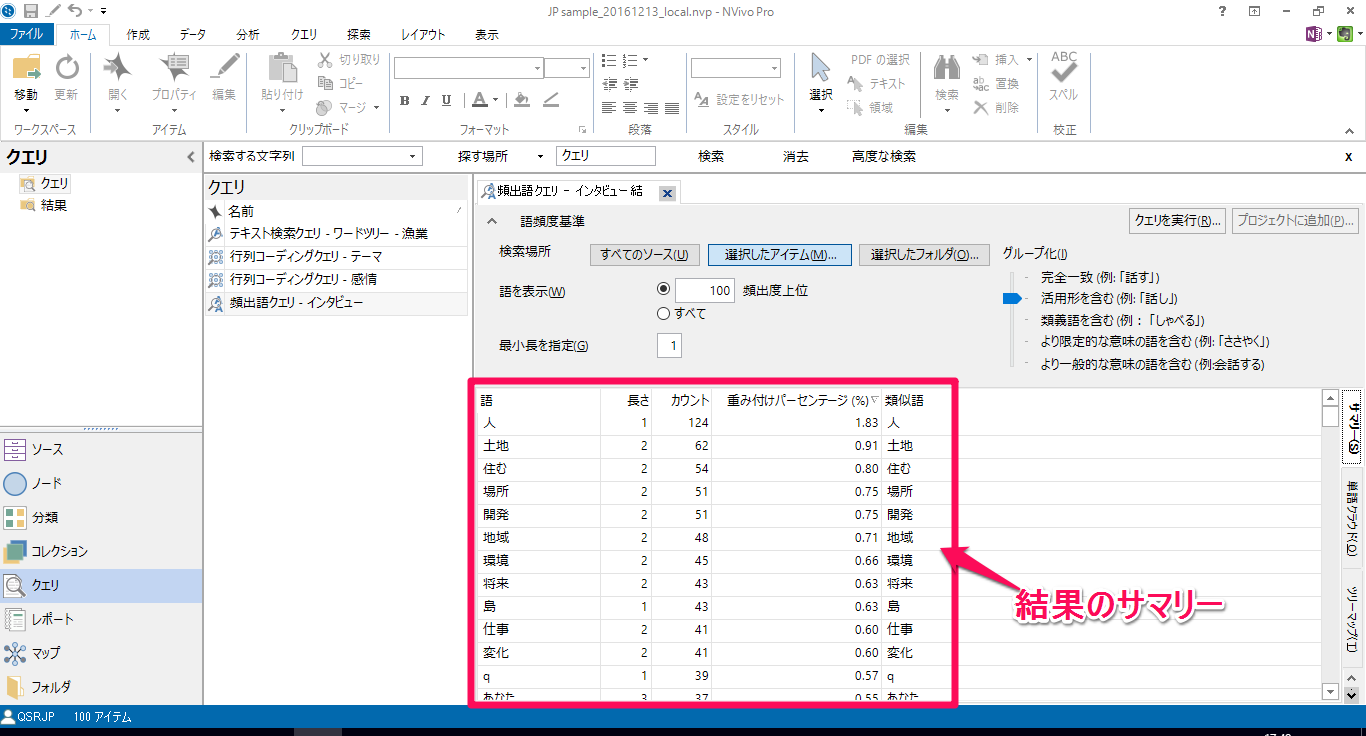
頻出語の結果が表示されています
この時点で英語しか表示されない場合には、頻出語で日本語が表示されない を参照して設定を切り替えたうえでクエリを再実行してみてください。
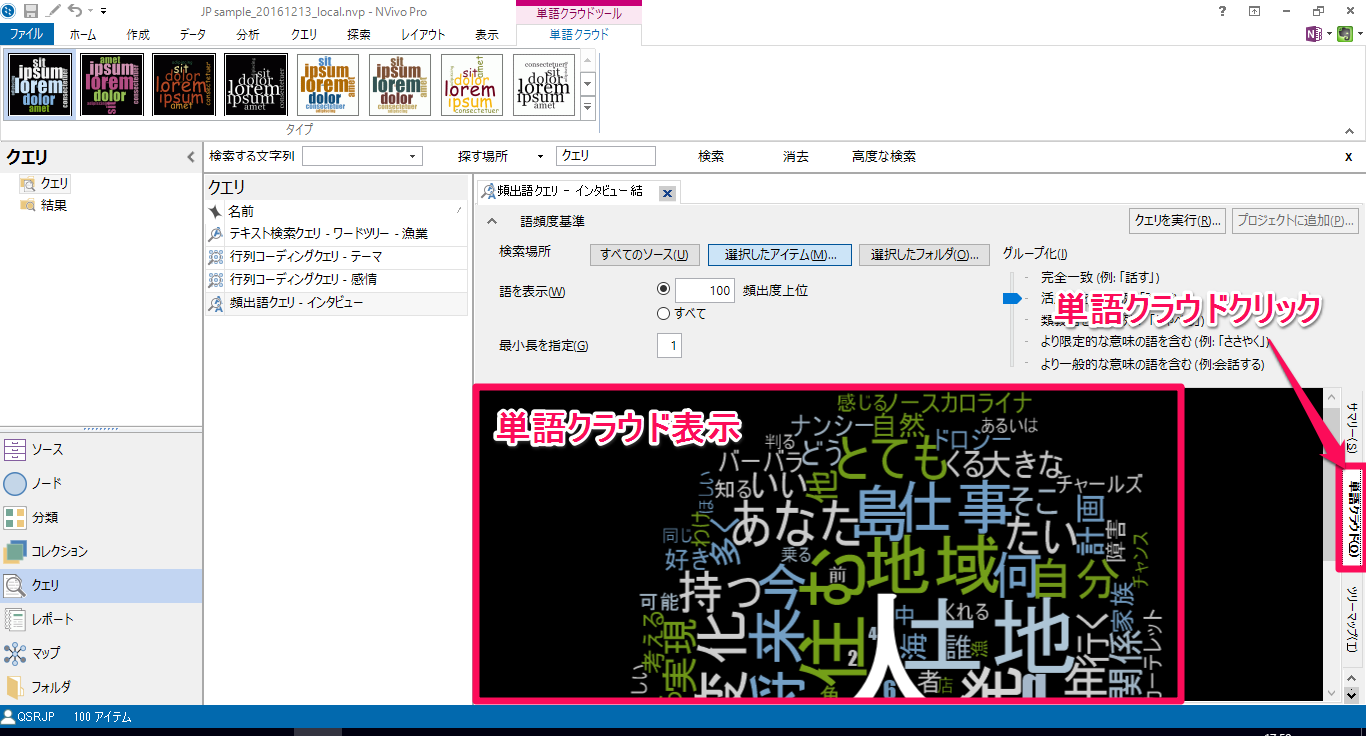
右側タブの「単語クラウド」をクリックすると表示が切り替わります
補足
- “プロジェクトに追加”にチェックを入れると、設定条件を保存して、何度も同じクエリを実行する場合に便利です。リンク先のヘルプもご覧になさってください。
- 気になる単語の上で右クリック → テキスト検索クエリ と辿ると、すばやくその単語を中心としたワードツリーの表示に事もできます。詳しくはワードツリーを表示するの2番目以降の手順をご参照ください。
以上です。ご不明点などありましたら、コメントください。
参照元 : NVivo Help > Run a word frequency query
関連記事
-

-
ワード頻出度クエリの設定変更
前回、ワード頻出度クエリで日本語設定をする方法を(ワード頻出度クエリで日本語が出ない→言語変更で解決
-
-
ワードツリーを最前面に – テキスト検索クエリ結果プレビュー
「テキスト検索クエリを実行したら、真っ先にワードツリーを見たい!」そんな時はテキスト検索クエリ結果プ
-

-
ワード頻出度クエリで不要な単語を非表示にする(停止語を使う)
ワード頻出度クエリを実行し、表示結果の中に研究に不必要な単語が出てくることがあります。例えばSNSの
-

-
ワード頻出度を表示する
ワード頻出度[/caption] この画像のように、取り込んだデータや特定のノードでコーディ
-
-
行列コーディングクエリ
行列コーディングはインポートされたデータ、コーディングされたデータを元に
-
-
テキスト検索クエリの結果をワードツリーで表示する
NVivo ではご自身の研究に必要なドキュメントから、単語を指定してその単語の前後でどのような事が述
-

-
コーディングクエリを使う
ノードをダブルクリックするとそこにコーディングされているテキストなどのリファレンスを見ることができま
-

-
テキスト検索クエリを使う
調査・研究で必要な資料が集まって、その中から特定の単語を探し出すというの
-
-
資料から一瞬で必要な文章を取り出す「テキスト検索クエリ」(NVivo 11)
調査・研究で必要な資料が集まって、その中から特定の単語を探し出すというのはとても骨の折れる作
-
-
クエリオプションを使いこなす – 対象範囲を指定する
クエリ設定画面[/caption] テキスト検索クエリやワード頻出度クエリには、検索条件とし