行列コーディングクエリ
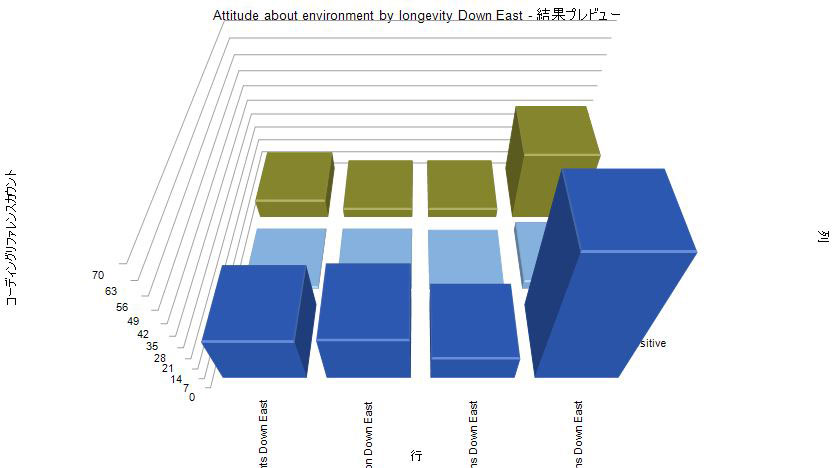
行列コーディングはインポートされたデータ、コーディングされたデータを元に、コーディングA x コーディングB など、条件を設定してデータを集計する機能です。この機能を駆使することにより、画像のようなグラフで出力することができます。では操作方法を見ていく事にしましょう。
*この記事はNVivo 10 for Windowsを使用して作成しました。NVivo 11 Pro ならびに Plus でも同じ手順で操作が可能です。
*NVivo10に付属のサンプルプロジェクトを利用します。
1.行列コーディングの起動
行列コーディングの選択
クエリ>行列コーディング と進めます。
2.行の定義をする
行列コーディング>行の定義
この画面では結果の行となる項目を定義します。”選択”をクリックしましょう。
3.要素となるアイテム選択
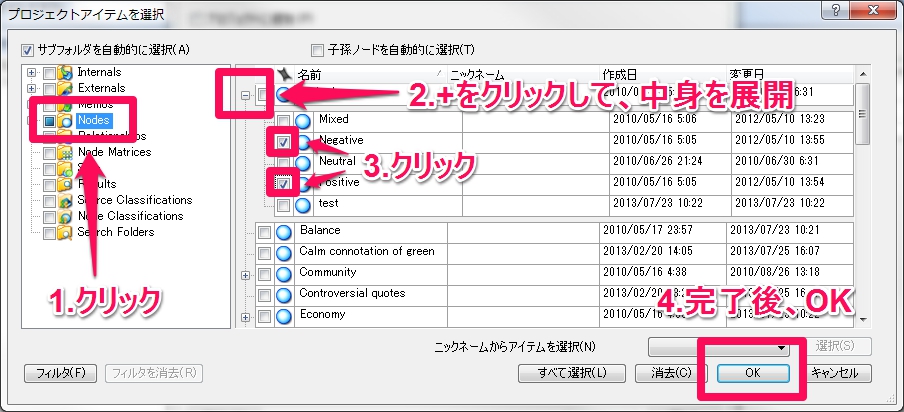
行列コーディング>行の要素選択
ここではノードで”Positive””Negative”ノードを選択し、OKをクリックします。
4.要素となるアイテムを追加
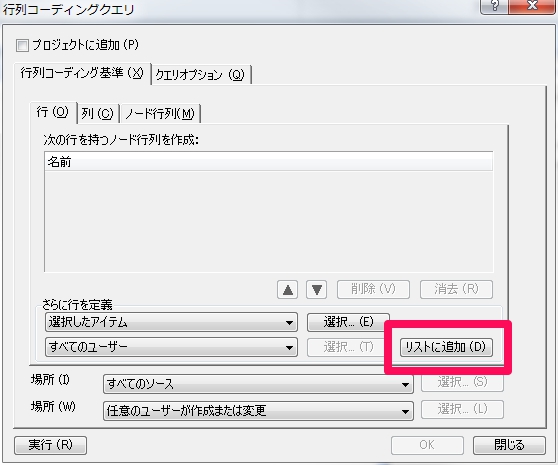
行列コーディング>行の要素追加
“リストに追加”をクリックします。
5.行の要素定義が完了
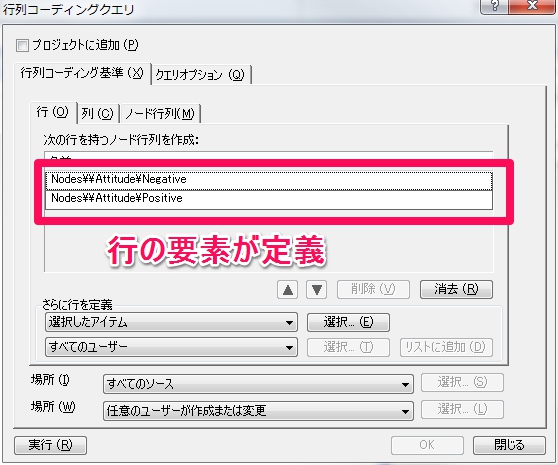
行列コーディング>行の定義完了
これで行の要素定義が完了しました。
6.列の定義
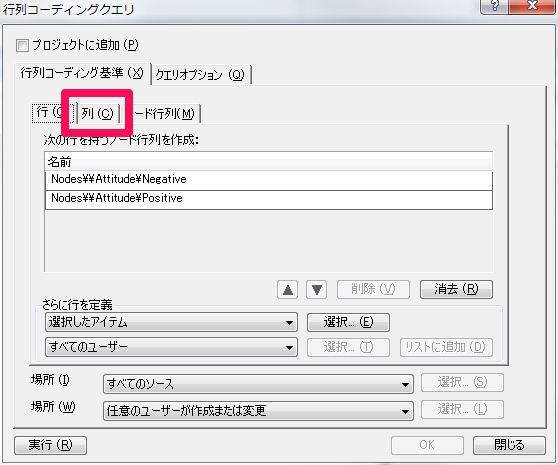
列の定義
列のタブをクリックして、2-5と同様の手順で進めます。選択アイテムは以下の画面のように”Search Folders”>次の4件、”Longevity-1st generation Down East”,”2 generations” “3+ generations” “Non-regsidents”を選択します。
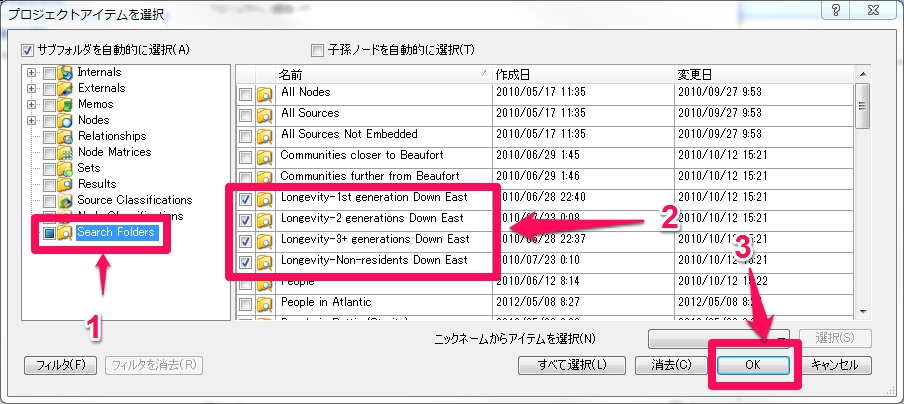
列の要素選択
7.列要素の決定
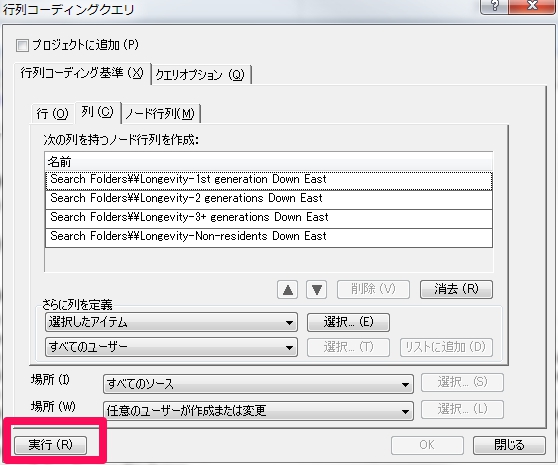
要素の定義完了
要素定義が完了したら、”実行”をクリックしましょう。
8.結果の表示
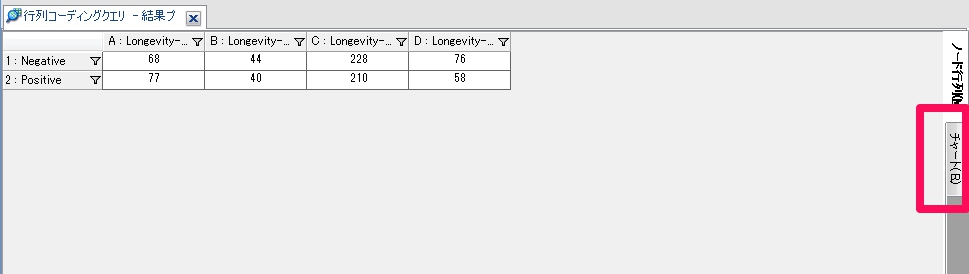
実行結果の表示
集計結果が表示されますので、右タブのチャートをクリックしましょう。
9.グラフの表示

- チャートの表示
- グラフ形式で表示されました。
- この行列コーディングでは、様々な設定ができるのですが、詳細は追って追記します。待てない方のためにヘルプへのリンクを置いておきます。
- NVivo 10 Help – Run a matrix coding

関連記事
-
-
クエリオプションを使いこなす – 対象範囲を指定する
クエリ設定画面[/caption] テキスト検索クエリやワード頻出度クエリには、検索条件とし
-
-
クエリを保存する方法
何度も使うクエリはクエリウィザードの設定中にクエリを保存しておくのが良いです。例えば一度分析したプロ
-

-
ワード頻出度クエリで不要な単語を非表示にする(停止語を使う)
ワード頻出度クエリを実行し、表示結果の中に研究に不必要な単語が出てくることがあります。例えばSNSの
-

-
単語クラウドを最前面に – 頻出語クエリ表示
頻出語クエリを実行すると、「サマリー」「単語クラウド」「ツリーマップ」「クラスター分析」の4つのビュ
-

-
頻出語クエリで日本語が表示されない(NVivo 11)
英語だけの単語クラウド[/caption] 頻出語クエリで日本語が出てこず、英語だけの結果が
-

-
コーディングクエリを使う
ノードをダブルクリックするとそこにコーディングされているテキストなどのリファレンスを見ることができま
-

-
頻出語を特定する(NVivo 11)
頻出語[/caption] 集めてきたデータを俯瞰してみてみたいとき、NVivoでは頻出語と
-

-
テキスト検索クエリで一括コーディング
NVivoでは単語を基準にして一括コーディングする機能があります。対象となるデータから漏れなく情報を
-

-
資料から一瞬で必要な文章を取り出す「テキスト検索クエリ」(NVivo 11)
調査・研究で必要な資料が集まって、その中から特定の単語を探し出すというのはとても骨の折れる作
-
-
ワードツリーを最前面に – テキスト検索クエリ結果プレビュー
「テキスト検索クエリを実行したら、真っ先にワードツリーを見たい!」そんな時はテキスト検索クエリ結果プ